Deprecation Note
We published the last version of Graylog Documentation before the release of Graylog 4.2. Now, all documentation and help content for Graylog products are available at https://docs.graylog.org/.
There will be no further updates to these pages as of October 2021.
Do you have questions about our documentation? You may place comments or start discussions about documentation here: https://community.graylog.org/c/documentation-campfire/30
Setup¶
Graylog Archive is a commercial feature that can be installed in addition to the Graylog open source server.
Installation¶
Archiving is part of the Graylog Enterprise plugin, please check the Graylog Enterprise setup page for details on how to install it.
Configuration¶
Graylog Archive can be configured via the Graylog web interface and does not need any changes in the Graylog server configuration file.
In the web interface menu navigate to “Enterprise/Archives” and click “Configuration” to adjust the configuration.
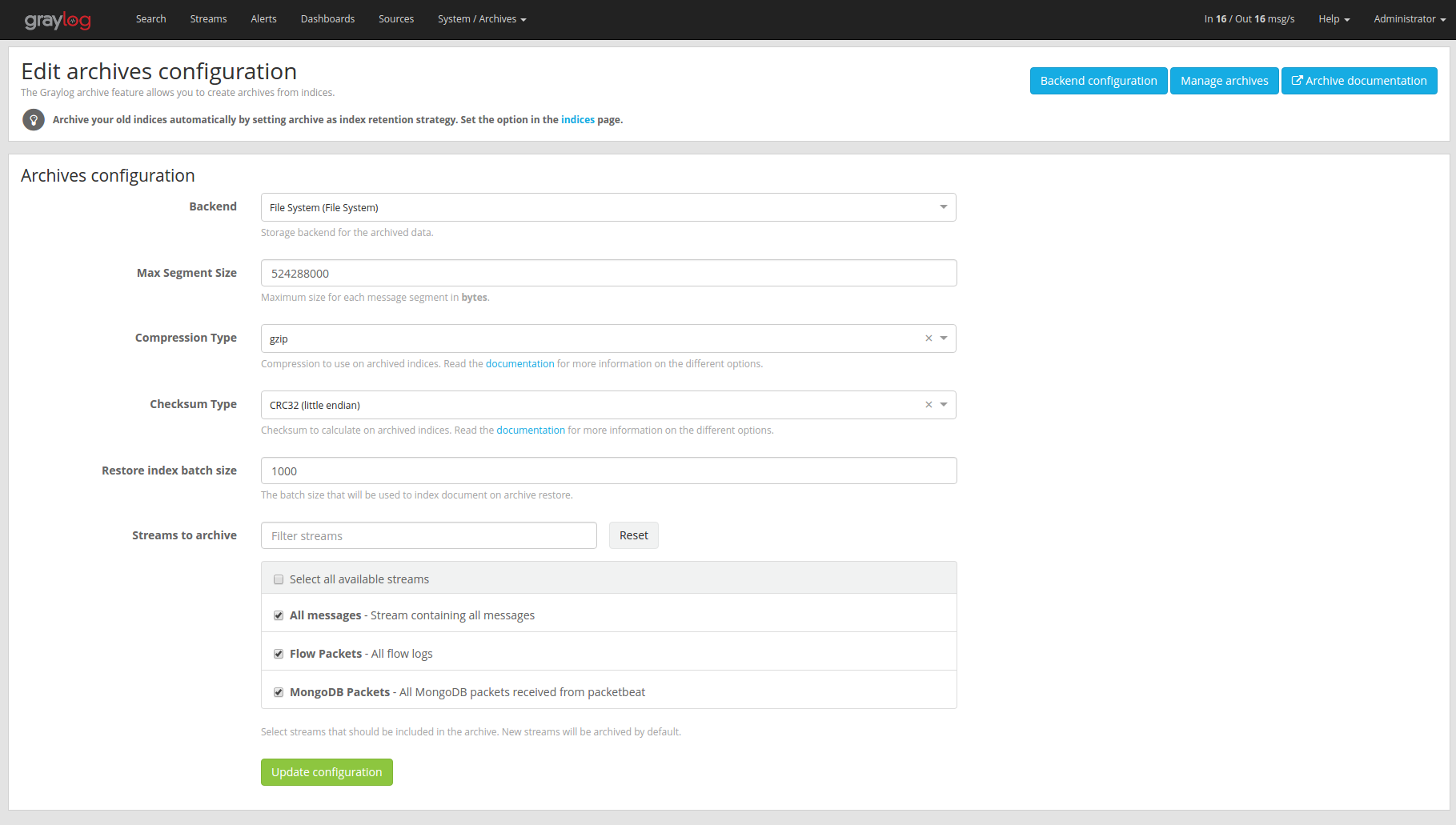
Archive Options¶
There are several configuration options to configure archiving.
Name |
Description |
|---|---|
Backend |
Backend on the master node where the archive files will be stored. |
Max Segment Size |
Maximum size (in bytes) of archive segment files. |
Compression Type |
Compression type that will be used to compress the archives. |
Checksum Type |
Checksum algorithm that is used to calculate the checksum for archives. |
Restore index batch size |
Elasticsearch batch size when restoring archive files. |
Streams to archive |
Streams that should be included in the archive. |
Backend¶
The archived indices will be stored in a backend. A backend that stores the data in /tmp/graylog-archive is created
when the server starts for the first time but you can create a new backend if you want to store the data in a different
path.
Max Segment Size¶
When archiving an index, the archive job writes the data into segments. The Max Segment Size setting sets the size limit for each of these data segments.
This allows control over the file size of the segment files to make it possible to process them with tools which have a size limit for files.
Once the size limit is reached, a new segment file will be started.
Example:
/path/to/archive/
graylog_201/
archive-metadata.json
archive-segment-0.gz
archive-segment-1.gz
archive-segment-2.gz
Compression Type¶
Archives will be compressed with gzip by default. This option can be changed to use a different compression type.
The selected compression type has a big impact on the time it takes to archive an index. Gzip for example is pretty slow but has a great compression rate. Snappy and LZ4 are way faster but the archives will be bigger.
Here is a comparison between the available compression algorithms with test data.
Type |
Index Size |
Archive Size |
Duration |
|---|---|---|---|
gzip |
1 GB |
134 MB |
15 minutes, 23 seconds |
Snappy |
1 GB |
291 MB |
2 minutes, 31 seconds |
LZ4 |
1 GB |
266 MB |
2 minutes, 25 seconds |
Note
Results with your data may vary! Make sure to test the different compression types to find the one that is best for your data.
Warning
The current implementation of LZ4 is not compatible with the LZ4 CLI tools, thus decompressing the LZ4 archives outside of Graylog is currently not possible.
Checksum Type¶
When writing archives Graylog computes a CRC32 checksum over the files. This option can be changed to use a different checksum algorithm.
The type of checksum depends on the use case. CRC32 and MD5 are quick to compute and a reasonable choice to be able to detect damaged files, but neither is suitable as protection against malicious changes in the files. Graylog also supports using SHA-1 or SHA-256 checksums which can be used to make sure the files were not modified, as they are cryptographic hashes.
The best choice of checksum types depends on whether the necessary system tools are installed to compute them later (not all systems come with a SHA-256 utility for example), speed of checksum calculation for larger files as well as the security considerations.
Restore Index Batch Size¶
This setting controls the batch size for re-indexing archive data into
Elasticsearch. When set to 1000, the restore job will re-index the
archived data in document batches of 1000.
You can use this setting to control the speed of the restore process and also how much load it will generate on the Elasticsearch cluster. The higher the batch size, the faster the restore will progress and the more load will be put on your Elasticsearch cluster in addition to the normal message processing.
Make sure to tune this carefully to avoid any negative impact on your message indexing throughput and search speed!
Streams To Archive¶
This option can be used to select which streams should be included in the archive. With this you are able to archive only your important data instead of archiving everything that is arriving in Graylog.
Note
New streams will be archived automatically. If you create a new stream and don’t want it to be archived, you have to disable it in this configuration dialog.
Backends¶
A backend can be used to store the archived data. For now, we only support a single file system backend type.
File System¶
The archived indices will be stored in the Output base path directory. This directory needs to exist and be writable for the Graylog server process so the files can be stored.
Note
Only the master node needs access to the Output base path directory because the archiving process runs on the master node.
We recommend to put the Output base path directory onto a separate disk or partition to avoid any negative impact on the message processing should the archiving fill up the disk.
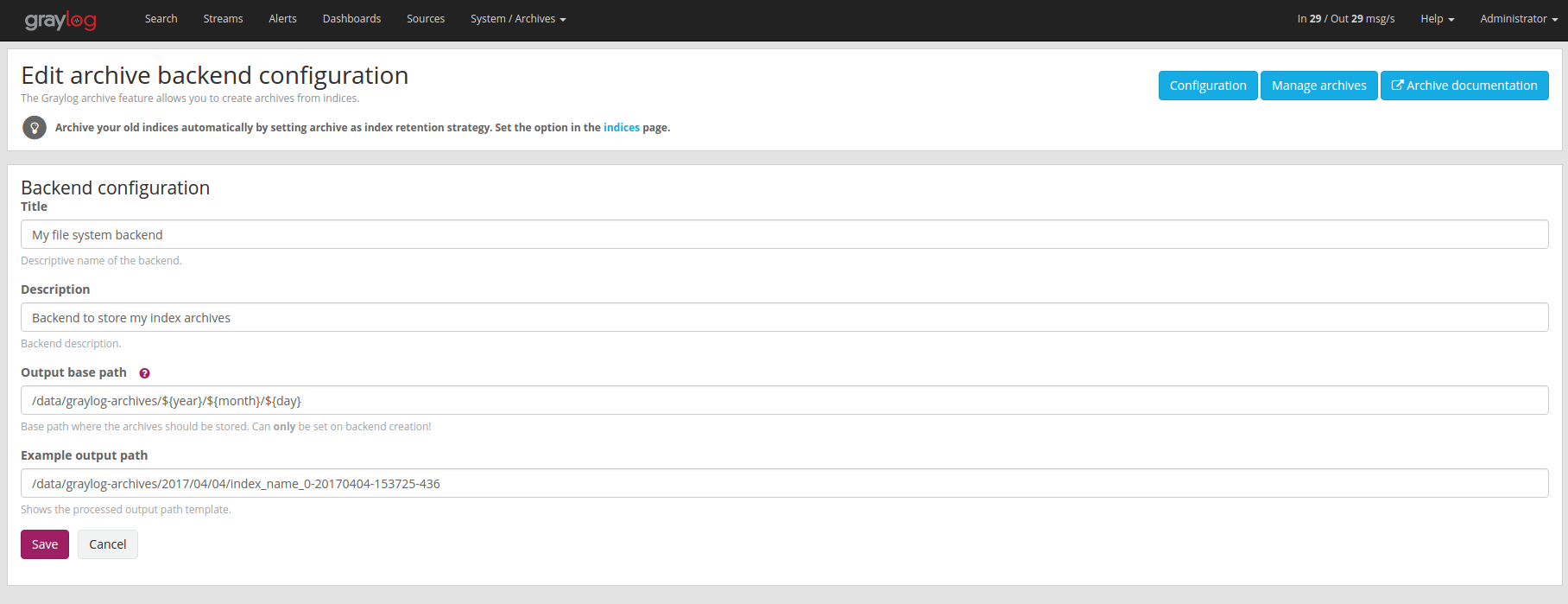
Name |
Description |
|---|---|
Title |
A simple title to identify the backend. |
Description |
Longer description for the backend. |
Output base path |
Directory path where the archive files should be stored. |
Output base path
The output base path can either be a simple directory path string or a template string to build dynamic paths.
You could use a template string to store the archive data in a directory tree that is based on the archival date.
Example:
# Template
/data/graylog-archive/${year}/${month}/${day}
# Result
/data/graylog-archive/2017/04/01/graylog_0
Name |
Description |
|---|---|
|
Archival date year. (e.g. “2017”) |
|
Archival date month. (e.g “04”) |
|
Archival date day. (e.g. “01”) |
|
Archival date hour. (e.g. “23”) |
|
Archival date minute. (e.g. “24”) |
|
Archival date second. (e.g. “59”) |
|
Name of the archived index. (e.g. “graylog_0”) |
Index Retention¶
Graylog is using configurable index retention strategies to delete old indices. By default indices can be closed or deleted if you have more than the configured limit.
Graylog Archive offers a new index retention strategy that you can configure to automatically archive an index before closing or deleting it.
Index retention strategies can be configured in the system menu under “System/Indices”. Select an index set and click “Edit” to change the index rotation and retention strategies.
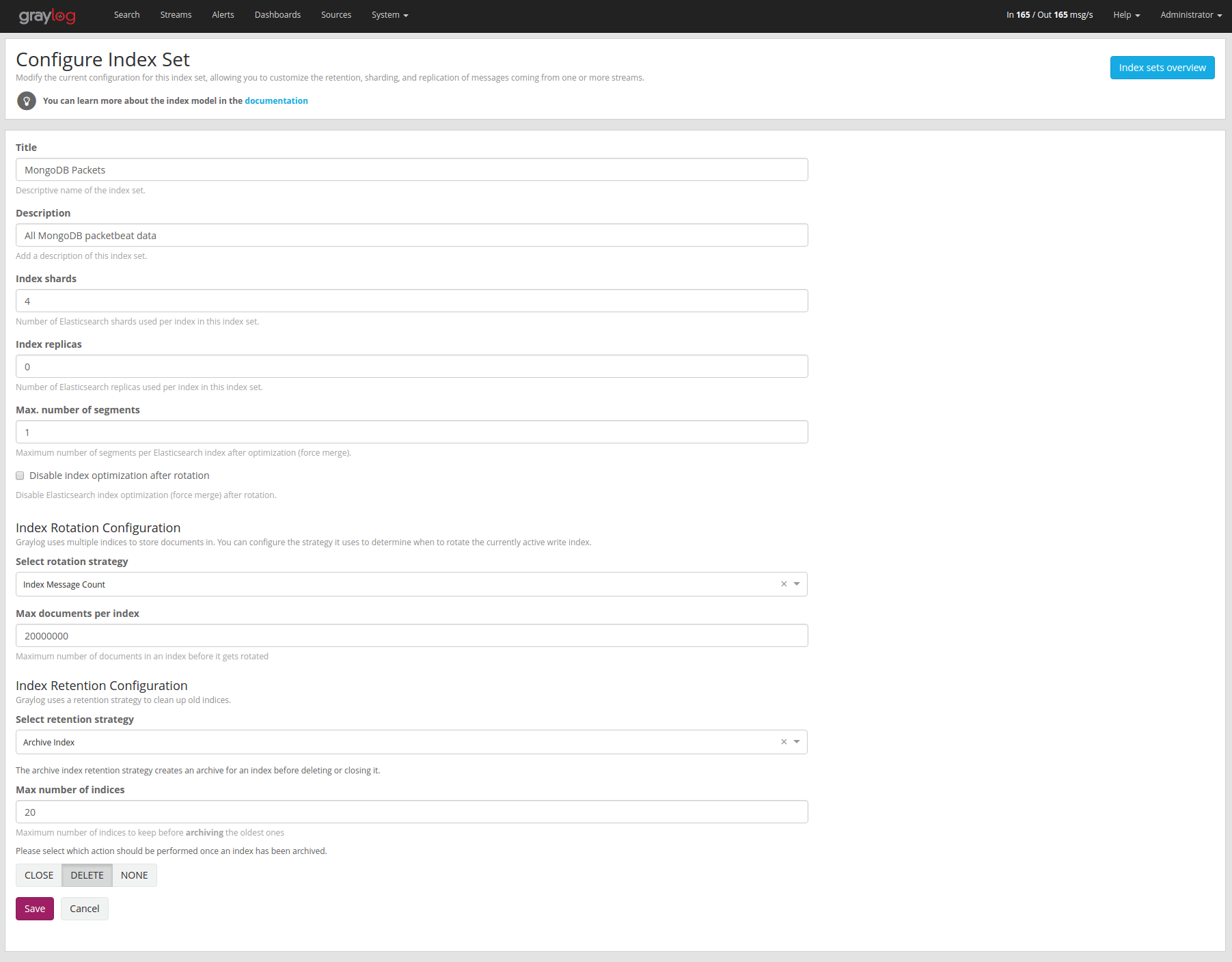
As with the regular index retention strategies, you can configure a max number of Elasticsearch indices. Once there are more indices than the configured limit, the oldest ones will be archived into the backend and then closed or deleted. You can also decide to not do anything (NONE) after archiving an index. In that case no cleanup of old indices will happen and you have to take care of that yourself!